


Ottó Haszpra
Liter-ofteco en Esperantaj tekstoj
Zusammenfassung
Buchstabenhäufigkeit in Esperantotexten
Der Autor wurde zu seiner Statistik über die Häufigkeit der Buchstaben in Esperantotexten durch neuerliche Diskussionen über die Notwendigkeit einer Modifizierung des Esperantoalphabets angeregt. Nach einer kritischen Übersicht über verschiedene Statistiken, die seit der Entstehung des Esperantos angefertigt wurden, beschreibt er die von ihm angewandte Methode und stellt sein Korpus von einer halben Million Buchstaben vor, das sich aus verschiedenartigen Korpora von je 20 000 Buchstaben zusammensetzt (Tabelle I). Es wird durch Beispiele gezeigt, dass die durchschnittliche Häufigkeit einzelner Buchstaben und ihre Standardabweichung vom Charakter eines Textes abhängen. Einige besondere Bemerkungen werden in Bezug auf Buchstaben mit diakritischen Zeichen gemacht.
Abstract
Frequency of Letters in Esperanto Texts
Prompted by recent debates on modifications to the Esperanto alphabet, a study was conducted on the frequency of letters in Esperanto texts. The article includes a critical overview of previous statistical studies and a new analysis based on a text corpus of half a million letters divided into corpuses of approximately 20,000 letters each (Table I). Both the average relative frequency of individual letters and its standard deviation are shown to depend on the character of the text. Some implications for the relative advantages of different writing systems for Esperanto are discussed.
1 Enkonduko
En la jaro 1999, instigite pro la kampanjo de iama prezidanto de la Akademio de Esperanto por fakte kontraŭfundamenta ,,internaciigo" de la Esperanta alfabeto (ekz.: Albault 1997), mi volis science studi la alfabetan problemaron kaj por tio mi bezonis ankaŭ iom precizan ofteco-liston de la Esperantaj literoj en tekstoj. Mi mem faris tian statistiketon pri la supersignitaj literoj en la 80-aj jaroj surbaze de kvar po ĉ. 6000-literaj tekstokorpusoj, beletraj kaj fakaj, originalaj kaj tradukitaj, kiu restis en formo de manskribitaj notoj. Mi trovis unu solan statistikon (Sherwood 1983) pri la ofteco de ĉiu el la 28 literoj de la Esperanta alfabeto, sed nur surbaze de same ne tre granda registrita teksto de duonhora viva konversacio kun 17.020 fonemoj (= literoj). Do mi decidis mem fari pli ampleksan statistikon. Post mallonga raporto pri la ĉefaj rezultoj (Haszpra 1999a), eĉ post la finpretigo de la unua versio de jena iom ampleksa artikolo - kiun mi sendis al kelkaj fakuloj - mi plu klopodis akiri fakliteraturon. Pluraj kolegoj, kiel Detlev Blanke kaj Máthé Árpád, Roy McCoy kaj Pejno Simono sendis al mi informojn, kaj ankaŭ mi mem trovis plurajn, ĉefe en la budapeŝta Fajszi-kolektaĵo. Do nun mi povas prezenti ankaŭ historian skizon, kvankam evidente ne kompletan.
2 Historia skizo
En la komenca periodo de Esperanto la homoj interesiĝis nur pri la kreskanta nombro da esperantistoj, grupoj kaj eldonaĵoj kaj tiu interesiĝo daŭras ĝis hodiaŭ (Statistiko 1933; Máthé 1988). Tamen komence de la 30-aj jaroj Stancliff jam faris tre grandan statistikan laboron pri la lingvo mem (Stancliff 1932; Vortstatistiko 1933). Surbaze de la Originala Verkaro de Zamenhof, du libroj de Baghy kaj po unu grandparte originala, parte tradukita libro de naŭ aliaj aŭtoroj li kalkulis la relativan ofton de la unuopaj prepozicioj rilate al ilia suma nombro kaj same li statistikis pri la korelativoj, la afiksoj kaj la prefikse uzataj prepozicioj.
Statistikon pri la nombro de diversaj vortspecoj (radikoj, afiksoj, finaĵoj) kaj komencliteroj, rilate al la oficialaj kaj neoficialaj radikoj, troveblaj en la Universala Vortaro kaj la Plena Vortaro kun Suplementoj, faris Ciliga (1961). Dum la lastaj jardekoj pluraj aŭtoroj aperigis statistikojn pri la ofteco de vortoj en skribitaj tekstoj kaj vivaj konversacioj.
En la sekvaj mi dediĉas mian atenton al la literstatistikoj.
Laŭ mia scio la redakcio (evidente la redaktoro, T. Jung) de la Heroldo de Esperanto (HdE ) (Jung? 1926) faris la unuan statistikon pri la ofteco de la literoj - surbaze de 20.000-litera Esperantlingva korpuso el ,,plej diversaj tekstoj" - por kunmeti ekonomian mendon de presejaj litertipoj por sia presejo. La plej ofta litero estis a kun ofto 12,110%, sekvis e, o, i kaj n kun 9,735, 9,095, 8,930 kaj 8,320%, resp.
Sep jarojn poste aperis statistiko (Stancliff, 1933) pri la ofteco de literoj en 33.000-litera korpuso el la libro Viktimoj de Baghy. (Ĉi lastan artikoleton la redakcio de HdE kompletigis per sia supre menciita statistiko kaj komparaj rimarkoj.) Ankaŭ laŭ Stancliff la plej ofta litero estis a kun 12,16%, poste i, o, e kaj n kun 11,48, 9,44, 9,01 kaj 8,39%, resp.
Fine de la 50-aj jaroj aperis studaĵo de Sadler pri la ofteco de lingvaj elementoj (Sadler, 1959). Li faris siajn kalkulojn pri la ofteco de la jam menciitaj afiksoj, korelativoj, sed ankaŭ pri tiu de la fonemoj de Esperanto. En sia studo li studis 3000 specimenojn (= vortoj) el prozaj tekstoj laŭhazarde prenitaj, en formo de verŝajne kelkcentvortaj korpusoj, hazarde elektitaj el la ,,fontoj", kiuj lastaj ,,inkluzivis sciencajn, beletrajn, fikciajn kaj ĝeneralajn verkojn, inter kiuj ne mankis ankaŭ Zamenhofaj". La teksto-elektado estis tute bona, nur la nombro de la vortoj estis iom malgranda. Transforminte tiun nombron al nombro de literoj, ĝi estas egala al ĉ. 15.000 literoj, ĉar laŭ mia - nur proksimuma - takso la averaĝa longo de la vortoj en Esperanta teksto - do ne en la vortaro! - estas ĉ. 5 literoj. (Laŭ Gledhill [1998]: 4,9 literoj.)
Rilate al nur la fonemoj, la studon de Sadler sekvis apoga raporteto (Harry 1967) post ok jaroj. Harry aplikis la metodon de Sadler same por 3000 specimenoj el 6 prozaj tekstoj de po 500 specimenoj laŭhazarde prenitaj el diversaj fontoj. Do temas pri studo de tekstokorpuso same de ĉ. 15.000 literoj, sed evidente la du "15.000" ne estas egalaj unu al la alia, nek al 15.000.
La metodo de Sadler kaj Harry analizi la nombron de la fonemoj estus malferminta vojon al la ofteco-statistiko de literoj, se ili konsiderus ĉiun literon kiel apartenaĵon de unu fonemo kaj inverse. Ja - laŭ Zamenhof, laŭ pluraj esperantologoj, ekz. Sherwood, kaj ankaŭ laŭ mi - en Esperanto estas 28 literoj kaj 28 fonemoj. Bedaŭrinde, Sadler, kaj sur lia spuro ankaŭ Harry, rigardis ŭ kiel u , c kiel ts, ĉ kiel tŝ kaj ĝ kiel dĵ , ,,ĉar en tio ne estas eblo de semantika konfuzo", kies diskutado ne estas objekto de jena artikolo.
Kiel rezulto de la ĉi supraj konsideroj, la (aparte ne konigita) apernombro de (la litero) ŭ aldoniĝis al la (aparte same ne konigita) apernombro de u, sed eĉ malpli feliĉe por la statistiko de la literoj la nombro de c aldoniĝis ne nur al tiu de t, sed ankaŭ al tiu de s. Same okazis pri ĉ kaj ĝ. Do la fonemoj (kaj literoj) ŭ, c, ĉ kaj ĝ tute malaperis, sed la apernombro de la fonemoj (kaj literoj) t, s, ŝ, d kaj ĵ kreskis pro la aldonoj, kaj rezulte la tuta apernombro kreskis, dum la proporcioj inter la fonemoj deformiĝis. La nombro de la fonemoj (kaj la literoj) reduktiĝis de 28 al 24 (inter kiuj restis du supersignitaj literoj: ĵ kaj ŝ). Tiamaniere, bedaŭrinde, la Sadler/Harry-a fonemo-statistiko ne konsidereblas litero-statistiko. Oni povas akcepti la rezultan ofteco-rangon nur inter la netuŝitaj literoj (fonemoj), sed ankaŭ ties relativa ofteco iĝis pli malpli falsa. Rilate al la tuŝitaj literoj, eĉ ties ofteco-rango povas esti falsa.
Do ilia statistiko en si mem estas prava pri tio, ke ekz. la plej ofta litero/fonemo (rango 1) estas a, la dua (rango 2) estas e, la tria (rango 3) estas i, sed ties relativaj oftoj (13,17%, 9,13% kaj 8,40%, respektive) jam enhavas numeralan eraron, do ne estas akcepteblaj. Estas alia afero, ke pro la malgrandeco de la korpusoj (po 3000 aŭ kune 6000 ,,specimenoj") la rezultoj multe pli povas devii de la rezultoj image riceveblaj el la ,,tuta" korpuso de la Esperantaj tekstoj, ol de tiuj riceveblaj el plurcentmil-literaj aŭ plurmilion-literaj korpusoj.
Estas menciebla pro ĝia specialeco la statistiko farita konekse kun kreo de inversa vortaro (Schlüter 1972). En la vortaro la radikvortoj - sen la kategorio-finaĵo - estas de-fine ordigitaj alfabete (... adob, lob, glob, snob, rob, mikrob, aprob, arb, barb, rabarb, farb, garb, karb, varb, cerb, herb, ...). En la vortaro troveblas literstatistiko de tiuj radikoj. Tio vere estas literstatistiko, sed certe ne tiu de ordinara tekstokorpuso. La ordo de la relativa oft(ec)o kun la respektivaj oftoj, kalkulitaj de mi el la donitaj absolutaj nombroj (el sume 45.987 literoj de 7.883 radikoj) estas proksimume: a: 9,7%, i: 9,6%, r : 8,7%, e: 8,1%, t: 7,45%, o: 7,1%, ... La leganto vidos el Tabelo II, ke ĉi tiuj nombroj tro malsamas de tiuj por normalaj tekstoj.
Malgrandan statistikeron pri verŝajne tre malgranda teksto aperigis sveda-finna duopo (Collinder/Setälä 1979), sed kun evidentaj eraroj rilate la partan mankon de la decimala punkto, pro kio ankaŭ la validaj ciferoj ŝajnas dubaj.
Mi jam publikigis, sur la paĝoj de la Debrecena Bulteno (Haszpra 1999), mallongan informon pri miaj statistikaj rezultoj pri la ofteco de la Esperantaj literoj. Sed poste mi ripetis, pliampleksigis kaj plidetaligis la studadon, faris rigorajn kontrolojn, kaj kvankam la bazaj rezultoj ŝanĝiĝis nur iomete, aŭ plejparte neniom, tamen nun la tuto estas pli preciza. Krome mi komputis pluajn parametrojn, kiuj kune ebligas fari bone bazitajn konkludojn. Intertempe mi malkovris ankaŭ la ĉi suprajn historiaĵojn.
Mi jam finis ĉi tiun historian skizon, kiam Roy McCoy konigis al mi du aliajn literstatistikojn nepublikigitajn (McCoy 1999). Unu surbaze de korpuso kun ĉ. 113 mil literoj - farita iam, en la Centra Oficejo de UEA, de persono, ne identigita kun certeco (eble V. Sadler) -, la alian, faritan de McCoy, surbaze de korpuso enhavanta ĉ. 4,5 milionojn da literoj de plur- (eble kvar-) jara tuta materialo de la jam perkomputile redaktita revuo Esperanto. Fine mi trovis statistikojn pri 100.000- kaj 313.000-literaj korpusoj (Kelly 1994, 1998), pri korpuso de 100.000 vortkomencoj (Gledhill 1998) kaj ricevis unu (Pejno 2000) pri 355.381-litera korpuso. Mi trovis statistikon de Setälä - kies originalon el 1980 mi ne povis vidi - pri 10.000 kaj tiun de Gicquel pri proksimume 100.000 literoj (Yung 1995).
Neniu el la menciitaj statistikoj analizis la variancajn deviojn aŭ aliajn karakterizilojn de la ofteco de la literoj. La utiligeblajn rezultojn el la ĉi supraj historiaĵoj mi prezentos en la Suplemento.
3 Bazoj, problemoj, metodoj
En la lastaj jaroj ankaŭ mi mem verkis kaj kompilis perkomputile lernolibron de Esperanto (Haszpra 1998, 2000), kun konsiderinda kolekto de ĉiutagaj, beletraj kaj sciencaj tekstoj, krome verkis sciencajn artikolojn kaj faris literaturajn tradukojn. Tiuj ĉi kune prezentas komputile prilaboreblan Esperantlingvan teksto-specimenaron de ĉ. duonmiliono da literoj.
Estas emfazinde, ke mi parolas nur pri literoj (en Esperanto unusence reprezentantaj fonemojn !), ĉar en tekstoj troviĝas ankaŭ diversaj signoj (punktoj, komoj, dupunktoj, krampoj, krisignoj, demandsignoj, citsignoj, apostrofoj, ligsignoj, ciferoj k.a., ne reprezentantaj fonemojn), kiuj por mia celo ne estis interesaj, sed kies ĉeesto iom malfaciligis la statistikumadon.
Per mia hejma persona komputilo, kun relative simpla teksto-redakta programo, principe ne estis problemo nombri, kiomfoje aperas kiu ajn opa litero de la alfabeto en ne tro longa teksto. Tamen nombri en unu paŝo ĉiujn literojn de la tuta tekstaro rekte ne eblis, ĉar la komputilo (sub misgvida termino ,,nombro de literoj") nombris la verajn literojn kaj la aliajn signojn kune. Do mi nombris en la teksto la aperojn de la opaj literoj de la 28-litera Esperanta alfabeto kaj poste sumis tiujn nombrojn por ricevi la tutan apernombron nur de la literoj. Subtrahinte tiun el la komputile donita sumo de la literoj kaj aliaj signoj kune, mi trovis ke la nombro de la supre menciitaj kaj aliaj signoj ĝenerale kreskigas inter 5 kaj 10 pocentoj la ,,netan" nombron de la literoj. Tiun problemon tamen mi ne studis en detaloj.
Mi konsideris neglektebla la sporadan ĉeeston de neesperantigitaj propraj nomoj (personaj, geografiaj k.a.) kaj de aliaj neesperantaj liter(grup)oj (matematikaj, kemiaj simboloj k.a.). Ties neesperantaj literoj (ekz. q, w, x, y, aŭ á, é, ő kaj aliaj) estis ellasitaj el mia statistiko, sed la aliaj (ekz. kemiaj simboloj CO, HO ) enestas.
Same nur supraĵe mi konstatis, ke la averaĝa longo de la vortoj en Esperanta teksto estas proksimume kvin literoj. Preciza nombro - sen forigo de ĉiu signo el la teksto - tamen ne estis ricevebla, ĉar la komputilo sub same misgvida termino ,,nombro de vortoj" fakte donis la nombron de liter-, signo-, cifero- kaj mikskonsistaj -grupoj, izolitaj disde la najbaraj grupoj de la limantaj ilin interspacoj en la teksto. Do tiuj grupoj, kvankam plejparte estas vortoj, tamen ne ĉiuj.
La prilaborotaj teksto-specimenoj surdiske disponeblaj estis elektitaj unuavice el mia lernolibro (Haszpra 1998), el kiu mi elektis la ,,Legaĵoj"-n de la 14 lecionoj (inkluzive la respektivajn esperantlingvajn ,,Taskoj"-n), krome ĉiujn literaturajn fragmentojn el la krestomatia parto. Mi prilaboris ankaŭ miajn apartajn beletrajn tradukojn kaj sciencajn kaj recenzajn artikolojn. Dum la unuaj provoj mi devis sperti, ke la komputilo ne kapablas unupaŝe nombri la tro oftajn literojn de la tuta tekstaro. Ekzemple ĝi nombris ĉ. -19 mil literojn a, kio jam simple pro la negativa antaŭsigno ne povis esti reala. Kiam mi dividis la ĉ. duonmilion-literan tutan tekstaron en kvin, ĉ. po centmil-literajn korpusojn, ties aparta nombrado sukcesis korekte kaj la sumo de la literoj a en la tuta tekstaro fariĝis ĉ. 63 mil kaj la aritmo de ties relativa ofto fariĝis la reala 12,59%.
Pro tio mi ekhavis la ideon dividi la tekstaron en pli multajn korpusojn (Tabelo I) por akiri ankaŭ ian karakterizan variancan devion de la relativa ofto de la opaj literoj. Mi pensis, ke ĉ. dudekmil-literaj korpusoj estus sufiĉe karakterizaj. Nek tro grandaj, nek tro malgrandaj. Do mi apartigis mian tekstaron en 24, proksimume po 20.000-literajn, korpusojn, tamen mi volis distranĉi neniun el la konsistigaj opaj teksto-specimenoj (granda parto de la korpusoj konsistis el po pluraj specimenoj) - eble en tio mi ne tute pravis -, do certaj korpusoj enhavis iom pli, aliaj iom malpli da literoj ol la ,,ideala" 20.000. Mi alprenis, kiel 25-an korpuson la registritan specimenon de viva konversacio de Sherwood, kiun fakte mi ne havis, sed el la suma nombro de ties ĉiuj fonemoj kaj el la pocentaĵo de la opaj fonemoj publikigitaj (Sherwood 1983) mi povis rekalkuli la nombron ankaŭ de la opaj fonemoj. Korpusojn 1 - 6 kaj 19 - 24 verkis aŭ tradukis mi, la aliaj korpusoj (7 - 18 kaj 25) estis de aliaj aŭtoroj aŭ tradukintoj. La amplekso de ambaŭ grupoj praktike estis la sama: ĉ. po kvaronmiliono da literoj. (Mi notas, ke la statistiko ne montris signifan diferencon laŭ la aŭtoroj, nur laŭ la temo aŭ karaktero de la tekstoj.) La aritmo de la liternombroj en la "20.000"-literaj korpusoj, kun ĝia varianca devio, estis 19.847 _ 2.321, la fakte spertitaj ekstremoj: 14.248 kaj 25.256.
Por kalkuli la aritmon F X de la relativa ofto de iu litero X de la tuta tekstaro, unue mi komputis la sumon nX de la nombroj nXi de X donitaj de la komputilo por ĉiu el la 25 korpusoj i, kaj poste dividis nX per la nombro N de ĉiuj literoj de la tuta tekstaro (N = 496.196), kio rezultigis FX. Poste mi kalkulis la relativan ofton fXi por ĉiu korpuso i kaj ties aritman mezon fX por la tuta tekstaro. Evidente f X iomete deviis disde FX, ĉar la korpusoj ne estis egalampleksaj. Sed tiun etgradan neegalecon mi juĝis neglektebla rilate ĝian efikon al la varianca devio. Do mi konsideris la korpusojn egalampleksaj por povi uzi la simplan varianco-komputan programon de mia komputilo. Tiel la kalkulita varianca devio teorie ne estis preciza, tamen praktike bone uzebla kiel varianca devio de FX.
Tabelo I
|
Listo de la analizitaj literaro-korpusoj |
||
|
Korpuso |
Karaktero (tre koncize) |
Liternombro |
|
1. Legaĵoj de Lecionoj |
Konversacioj, teknika diskuto, fiziko, gefianĉoj |
17.189 |
|
2. 5-6 |
Vojaĝo kaj geedziĝo en Havajio, fiziko |
14.248 |
|
3. 7-8 |
Surfado, matematiko, teknika kunsido, mekaniko |
19.271 |
|
4. 9-10 |
Scienca kaj Esperanta prelegvojaĝo en Ĉinio, kemio |
21.245 |
|
5. 11-12 |
Historiaĵoj en Ĉinio, homa korpo, agrikulturo, komputilo |
19.020 |
|
6. 13-14 |
Intertraktado, Operejo, sulfata acido, akademio, balo |
25.276 |
|
7. Belliteraturaj fragmentoj tradukitaj |
18 versaĵoj kaj prozaĵoj el la -XXXa ... XVIIa jc. |
21.511 |
|
8. |
27 versaĵoj, prozaĵoj el la XVIIa ... XXa jc. |
20.426 |
|
9. |
9 versaĵoj, prozaĵoj el la XXa jc. |
17.835 |
|
10. |
9 versaĵoj, prozaĵoj el la XXa jc. |
21.986 |
|
11. Belliteraturaj fragmentoj originalaj |
17 versaĵoj, prozaĵoj el la periodo 1887 ... 1950 |
20.748 |
|
12. |
10 versaĵoj, prozaĵoj el 1950 ... 1965 |
21.861 |
|
13. |
7 versaĵoj, prozaĵoj el 1960 ... 1998 |
18.042 |
|
14. Sciencaj fagmentoj, originalaj kaj tradukitaj |
11 fragmentoj el la periodo -Xa jc ... 1950. |
18.579 |
|
15. |
7 fragmentoj el 1950 ... 1970 |
19.124 |
|
16. |
5 fragmentoj el 1970 ... 1984 |
18.943 |
|
17. |
3 fragmentoj el 1980 ... 1987 |
19.033 |
|
18. |
7 fragmentoj el 1988 ... 1998 |
21.324 |
|
19. Beletraj tradukoj |
La Leaotungaj hometoj, 1895/1996 |
20.554 |
|
20. |
Leaotung, Verne (orig. rec.), 1895/1996, 1999 |
18.432 |
|
21. |
La nova bienulo, 1870/1999 |
20.538 |
|
22. |
La nova bienulo, Dúl Mihály, 1870, 1857/1999 |
20.043 |
|
23. |
Dúl Mihály, Pri HEM (orig. sc.), 1857/1999, 1999 |
24.499 |
|
24. |
Originalaj sc. artikoloj Modeleksperimentoj ..., Perforitaj tuboj ..., 1999 |
19.449 |
|
25. Viva konversacio |
Viva konversacio de Sherwood, 1983 |
17.020 |
|
Sume |
496.196 |
|
4 Rezultoj
La finrezultojn de la tuta statistiko pri la relativa ofteco de la apero de la opaj literoj (sen diferencigo inter majuskloj kaj minuskloj) de la alfabeto en Esperanta teksto prezentas Tabelo II en numerala formo. En tiu tabelo post ĉiu litero (lit.) sekvas en pocentoj (= %) la aritmo de ĝia relativa ofto (F) rilate al la tuta tekstaro (24 korpusoj de la lernolibro de Haszpra, sume kun 479.176 literoj, plus 1 korpuso de Sherwood kun 17.020 literoj, totalo: 496.196 literoj) _ ties varianca devio (s) rilate al la po ĉ. 20.000-literaj korpusoj. En la sekva kolono estas la praktikaj ekstremoj de la relativa ofto kalkulitaj kun triobla varianca devio (F-3s kaj F+3s), poste la fakte spertitaj ekstremoj de la relativa ofto en la 25 korpusoj ( Fmin kaj Fmax), fine enparenteze la relativa ofto en la korpuso de Sherwood (FSh ). Inter ĉi lastaj tri estas substrekitaj tiuj, kiuj estas ekster la praktikaj ekstremoj.
Tabelo II
Mi mencias, ke la majuskloj ne havas rolon el vidpunkto de parolo. Por presejaj celoj tamen ilia ofto F% - kalkulita el la 479.176-litera korpuso - povas esti interesa (Tabelo III).
Tabelo III
|
lit. F % L 0,309 K 0,259 E 0,206 S 0,197 M 0,178 H 0,168 |
T 0,161 P 0,158 N 0,144 A 0,127 D 0,112 V 0,094 I 0,094 |
J 0,092 G 0,068 O 0,066 F 0,065 B 0,058 R 0,057 C 0,040 |
U 0,035 Z 0,013 ............... Ĉ 0,083 Ĝ 0,033 Ŝ 0,0159 |
Ĥ 0,0012 Ĵ 0,00063 Ŭ 0,00000 |
Jam el Tabelo II videblas, sed Figuro 1 pli okulfrape montras, kiel la varianca devio s de la aritmo F de la relativa ofto dependas de F mem. Konstateble, la plejparto de la punktoj (F,s) estas akumulita en mallarĝa zono laŭ la rekta trendlinio, donebla per la ekvacio
(1) s = 0,12 + 0,06333F _ 0,07.
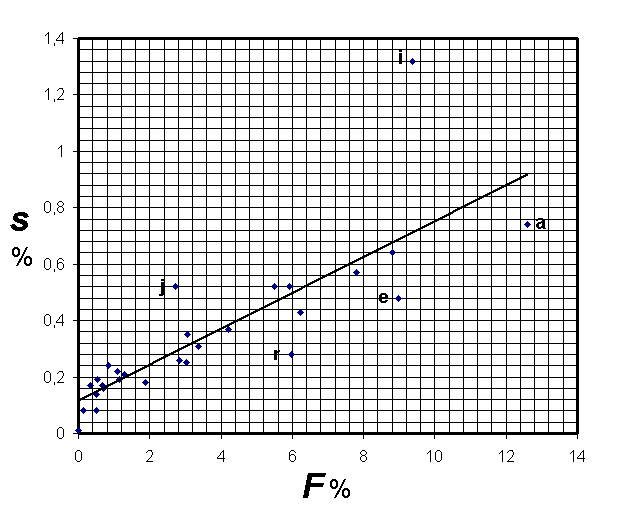 Fig. 1: Rilato inter la aritmo F de la relativa ofto kaj
ties varianca devio s
Fig. 1: Rilato inter la aritmo F de la relativa ofto kaj
ties varianca devio s
Tamen la aritmo de la relativa ofto de la literoj r, e, kaj a havas ekstreme malgrandan variancan devion (60-80%-ojn de la ,,normala"), dum j kaj i ekstreme grandan (preskaŭ duoblon de la ,,normala"). Pri ĥ ni ne diskutu, ĉar ĝi havas tiel malgrandan oftecon, ke eĉ duonmilion-litera teksto ne estas sufiĉa por akiri kontentigan fideblecon pri ĝia relativa ofto kaj ties varianca devio.
La laŭtrenda varianca devio signifas, ke ĝi - en la respektiva lingvo - ,,normalmezure" (pli malpli proporcie aŭ lineare) dependas nur de la aritma relativa ofto de la litero, sed ne de la teksto-karaktero, ekz. laŭforma (konversacio, rakonto, raporto, poemo k.a.), laŭenhava (ĉiutagaĵoj, fabelo, diversfaka sciencaĵo k.a.), laŭstila (konciza, malkonciza, klara, konfuza, ceremonia, simpla k.a.) ktp.
Se la varianca devio estas pli malgranda ol la trenda valoro, la sendependeco estas pli forta. (Varianca devio 0 signifus absolutan sendependecon_ la relativa ofto de la koncerna litero estus la sama en korpuso de kiu ajn karaktero.) Se la varianca devio estas pli granda ol la trenda valoro, tio signifas fortan dependecon disde la karaktero de la teksto.
Mi ne profundiĝis en tiu temo, ja ĝi estas tasko por lingvistoj. Ideoj pri la aplikado de la statistiko troviĝas ankaŭ en la pritraktitaj referencoj. Tamen mi skizas du ekzemplojn.
1. La litero i - kies aritmo de relativa ofto estas 9,36%, kaj ties varianca devio estas preskaŭ duobla kompare al la trenda valoro - havas relativan ofton pli malgrandan ol 9,36% en 4 sciencaj kaj 4 lecionaj korpusoj. Ĝi havas relativan ofton inter 8,36% kaj 10,36% en 2 sciencaj, 2 lecionaj, 1 viva konversacia (Sherwood), 6 mondliteraturaj kaj 1 originale verkita korpusoj. Ĝi havas relativan ofton pli grandan ol 10,36% en 3 mondliteraturaj kaj 2 originale verkitaj korpusoj (la maksimuma ofto troviĝis en unu el ĉi lastaj du).
Se kuraĝiĝinte ni dividas la oftojn nur en du grupojn: sub kaj super la aritmo 9,36%, ni vidas, ke ĉiu el la 9 mondliteraturaĵoj, 3 originalaj literaturaĵoj kaj la Sherwood-a viva konversacio, krome 1 el la 6 lecionaĵoj havas pli malaltan ofton de i ol ties aritmo, dum ĉiu el la 6 sciencaĵoj kaj 5 el la 6 lecionaĵoj havas pli altan ofton de i ol ties aritmo. Tio estas - almenaŭ parte - pro tio, ke en beletro (ĉefe rakontoj, romanoj) kaj rakontkaraktera konversacio la is-tempo estas preferata, dum sciencaj traktadoj (temis plejparte pri natursciencoj kaj tekniko) kaj demandaj kaj opini- aŭ instrukci-esprimaj konversacioj preferas aliajn verboformojn.
2. La litero e - kies aritmo de relativa ofto estas 8,99%, kaj ties varianca devio estas nur ĉ. 2/3 de la trenda valoro - havas relativan ofton pli malgrandan ol 8% en neniu korpuso, inter 8% kaj 10% en 24 korpusoj, pli grandan ol 10% en la sola korpuso de surbendigita viva konversacio (Sherwood 1983) kun valoro 11,4%, forte super la praktika ekstremo 10,44%.
Se ni forlasus ĉi lastan specimenon el nia statistiko, tiam la litero e havus eĉ pli malgrandan variancon, do montriĝus eĉ malpli dependa disde la karaktero de la teksto ol nun. Tio ŝajnas prava, ĉar la plioftiĝo de e certe signifgrade estas sekvo de la apero de adverboj, kaj ŝajnas ke la proporcio de adverboj ne tro dependas de la karaktero de la teksto. Tamen ni hazarde povis inkludi en nian statistikon tre specialan tekston: tiun de viva konversacio. Kaj la statistika analizo montras, ke la litero e en tiu sola korpuso ne nur pli oftas, sed ankaŭ fariĝis la plej ofta (11,4%), eĉ iom pli ofta ol a (11,3%), kiu lasta cetere ĉampione pruviĝis la plej ofta litero senescepte en ĉiu el la aliaj 24 korpusoj. Do ni vidas, ke en viva konversacio la litero e estas tiom ofta, ke ununura tia korpuso povas signife kreskigi ĝian aritman relativan ofton kaj ties variancon, kvankam eĉ tiel la varianco restis konsiderinde pli malalta ol la trenda valoro. Mi supozas, ke la kaŭzo de la ekstreme ofta apero de e en viva konversacio estas la multaj jes kaj ne, eble ankaŭ bone kaj tre kaj aliaj e-finaj adverboj.
Estas notinde, ke Sherwood esprimis perletere sian dubon pri la lineareco de la rilato inter s kaj F. Li - surbaze de teoriaj konsideroj - esprimis sian opinion, ke la rilato devas esti kvadratradika. Fakte, laŭ mia kalkulo, la radik-eksponento estas nur ĉ. 1,8. Laŭ mia opinio la ofto de la opaj literoj ne estas pure probableca variablo, ĉar la karaktero de la teksto - kiel estis videble ĉi supre - havas regulecan efikon al la probableco. Tio do influas la valoron de la eksponento. Mi ne emis okupiĝi pri teoria studado de la rilato, do elektis la plej simplan (kaj sufiĉe ilustrativan) linearan korelacion, sed eĉ el tio mi ne faris konkludojn.
Estas multaj aliaj aferoj pri kiuj la plua studado de la ĉi supra statistiko, aŭ plua analizo de la studitaj kaj pluaj korpusoj povas doni interesajn informojn aŭ gvidas al interesaj konkludoj. Ekzemple, ke 43,04%-oj de la literoj/fonemoj en teksto estas vokaloj, 56,96%-oj estas konsonantoj. El tio kaj el la ofteco de la kunmeto de certaj konsonantoj oni povas konkludi pri la flueco de Esperanto kompare kun aliaj lingvoj, ĉu al kiuj ĝi estas proksima, de kiuj malproksima ktp. Mi prezentas ankoraŭ kelkajn rezultojn nur pri la supersignitaj literoj.
5 Iom pri la supersignitaj literoj
Estas aparte interese rigardi la relativajn oftojn de niaj supersignitaj literoj. La sumo de la relativaj oftoj de la ses supersignitaj literoj (minuskloj kaj majuskloj kune) estas nur 2,38%. (En teksto inter 42 literoj averaĝe troviĝas nur unu el la ĉapelitaj literoj.)
En la tuta ĉ. duonmilion-litera teksto la supersignitaj minuskloj aperis jene: ĝ kun 0.66% (unu ĝ inter 151 literoj), ĉ kun 0,59% (unu ĉ inter 170 literoj), ŭ kun 0,51% (unu ŭ inter 196 literoj, preskaŭ ĉiam en la diftongoj aŭ, eŭ), ŝ kun 0,34% (unu ŝ inter 294 literoj), ĵ kun 0,15% (unu ĵ inter 667 literoj), ĥ kun 0,01% (unu ĥ inter 10.000 literoj).
Iom rondigitaj nombroj pri la supersignitaj majuskloj: La ofto de Ĉ estis 0,083% (do averaĝe unu Ĉ inter 1200 literoj), tiu de Ĝ: 0,033% (unu Ĝ inter 3000 literoj), tiu de Ŝ: 0,0159% (unu Ŝ inter 6300 literoj) kaj tiu de Ĥ: 0,0012% (unu Ĥ inter 88.000 literoj). Ĵ nur trifoje aperis (do ĝia ofto - se tio havas sencon - estis 0,00063%: unu Ĵ inter 160.000 literoj) kaj Ŭ tute ne aperis. (Tio kompreneble ne signifas, ke ili ne estas bezonataj.)
Surbaze de 239.412-litera mikstema korpuso mi trovis, ke la silabkomenca ŭ aperis kun ofto 0,0104% (unu inter 9700 literoj). Tio ĉi estas la tre maloftaj kazoj, preskaŭ ekskluzive en fremdaj nomoj (ŭato, Kame|ŭa|ŭa, ŭono, Jŭe ), kiam la prononco de ŭ iomete diferencas de la supre menciita, relative ofta (0,50%) kazo, kiam ŭ estas silabfina (hodiaŭ, Eŭ ropo).
Koncerne ĵ, mi ankoraŭ aldonas, ke - surbaze de mia porokaza kalkulo el 400.000-litera mikstema korpuso pri sciencoj kaj belliteraturo - la relativa ofto de la ĵ apartenanta al la trilitero aĵo estas 0,114%, kio praktike aperas pro la afikso -aĵo, ĉar draĵo kaj kaĵo ne aperis en la korpuso. Kune kun la derivitaj formoj -aĵa, -aĵe, -aĵu la pocentaĵo kreskis al 0,12% (80% el la relativa ofto 0,15% de ĵ). Do por la ĵ de la malpli ol 50 aliaj ĵ-havaj radikoj de PIV restas la kuna relativa ofto 0,03% (unu tia ĵ inter 3300 literoj).
Konkludojn rilatajn ne al la tereno de statistiko, mi aparte formulis (Haszpra 1999a,b).
6 Suplemento
En jena Suplemento mi konigas la rezultojn de tiuj literstatistikoj, kiuj rilatas al kontinuaj normalaj tekstoj kaj do estas kompareblaj kun la mia. Do mi forlasas la oftectabelon de la rimvortaro de vortradikoj (Schlüter 1972), ĉar ĝi ne estas karakteriza pri la kontinuaj Esperantaj tekstoj. Same ne uzeblas la fonemstatistiko pri la 100.000-vorta korpuso de Gledhill (1998), ĉar ĝi konsideris nur la komencajn kelkajn (eble 4?) literojn de la vortoj. (Collinder/Setälä 1979) estas nekompleta kaj ne spegulas sciencan zorgemon. La 10.000-vorta statistiko de Setälä (Yung 1995) estis kelkloke distordita per la alfabeto proponita de Yung kaj Gicquel, do ne uzebla. Mi ne prezentas la vortstatistikojn.
(1) La statistiko de Heroldo de Esperanto (Jung? 1926)
Litero nombro en %
a 2422 12,110
e 1947 9,735
o 1819 9,095
i 1786 8,930
n 1664 8,320
r 1185 5,925
s 1151 5,755
t 1120 6,600
l 1107 5.535
k 803 4,015
d 675 3,375
j 657 3,285
u 594 2,970
m 582 2,910
p 556 2,780
v 406 2,030
g 270 1,350
c 217 1,085
f 200 1,000
b 199 0,995
ĝ 138 0,690
ĉ 124 0,620
z 111 0,555
ŭ 96 0,480
h 91 0,455
ŝ 58 0,290
ĵ 16 0,080
ĥ 6 0,030
S: 20000 100,000
(2) La statistiko de F. Stancliff (Stancliff 1933) (kun listigo de la literoj laŭ ofteco-ordo en anglaj tekstoj). La pocentaĵojn kalkulis mi.
Esperanta % Angla
a 4019 12,16 e
i 3795 11,48 t
o 3119 9,44 a
e 2976 9,01 o
n 2774 8,39 n
s 2126 6,43 i
r 1947 5,89 r
t 1696 5,13 s
l 1622 4,91 h
k 1178 3,56 d
m 1116 3,38 l
u 990 3,00 c
d 885 2,68 u
p 834 2,52 f
v 840 2,54 m
j 794 2,40 p
b 382 1,16 w
f 291 0,88 g
g 280 0,85 v
ĉ 277 0,84 y
h 276 0,84 b
ĝ 180 0,54 x
ŝ 161 0,49 q
z 147 0,44 z
ŭ 142 0,43 j
c 134 0,41 k
ĵ 65 0,20
ĥ 0 0,00
S: 33046 100,00
(3) La statistiko de iama oficisto (V. Sadler?) de la CO de UEA (McCoy, 1999)
Specimeno de 112.806 literoj (en%)
12.49 A
9.50 E
8.83 O
8.81 I
7.31 N
6.12 L
5.75 S
5.53 R
4.18 K
3.58 J
3.26 M
3.19 U
3.19 P
2.77 D
1.49 V
1.48 G
1.01 F
0.98 B
0.93 C
0.61 Ĝ
0.58 Ŭ
0.58 Z
0.55 Ĉ
0.37 H
0.30 Ŝ
0.15 Ĵ
0.02 Ĥ
0.02 W
0.01 X
0.01 Q
0.00 Y
(4) La statistiko de R. McCoy (McCoy 1999):
Specimeno de 4.505.859 literoj
a 550284 12.21%
e 438754 9.74%
o 426050 9.46%
i 370762 8.23%
n 360592 8.00%
r 289495 6.42%
l 257811 5.72%
t 241831 5.37%
s 236310 5.24%
k 179340 3.98%
j 155365 3.45%
d 151959 3.37%
u 140305 3.11%
p 138698 3.08%
m 122838 2.73%
v 78299 1.74%
g 73203 1.62%
c 54842 1.22%
b 51408 1.14%
f 46294 1.03%
z 30787 0.68%
h 24793 0.55%
ĉ 21538 0.48%
ĝ 21065 0.47%
ŭ 20038 0.44%
ŝ 6703 0.15%
ĵ 5068 0.11%
w 4747 0.11%
y 4591 0.10%
x 1035 0.02%
ĥ 581 0.01%
q 473 0.01%
Komuna karakterizo de la ĉi supraj statistikoj estas, ke la aŭtoroj ne detaligis la (eble) sekvitajn elektajn principojn de la specimenoj kaj krom la oftoj ili ne kalkulis kian ajn karakterizilon.
Estas favora sperto, ke la donitaĵoj troveblaj en la ĉi supraj tabeloj estas bone en la plej mallarĝaj varianco-zonoj de mia statistiko. Laŭ la kvar statistikoj la aritmoj (ĉar nur tiuj estis kalkulitaj) de la relativa ofto, apartenantaj al 57 ... 75%-oj de la opaj literoj troviĝas en mia zono F _ s, ĝis 65-97%-oj en mia zono F _ 2s, ĉiuj literoj troviĝas en mia zono F _ 3s. Escepto estas la statistiko de Stancliff (kiu rilatis al nur unu libro de unu aŭtoro), el kiu nur 90%-oj troviĝis ene de F _ 3 s. Ankaŭ Stancliff falis 100%-e en mian zonon F _ 4s.
Rilate la supersignitajn literojn, ties suma relativa ofto en la ĉi supraj kvar statistikoj estas inter 1,67% kaj 2,71%, kompare kun mia 2,38%, kaj unuope falas preskaŭ senescepte en mian zonon F _ s.
La ĉi supra resuma prijuĝo ne nepre validas por la du sekvaj statistikoj, ĉar unu el ili baziĝas nur sur proza belliteraturo (kio okulfrape montriĝas en la ekstreme alta ofto de i), dum la alia enmiksis malĝustan fonemo-difinon en la aferon de literoj.
(5) La statistikoj de T. Kelly (Kelly 1994, 1996):
Por la unua statistiko li kun sia kunulino havis "novelaĵon el la angla kaj ĉina antologioj" de 37.000 vortoj kun 100.503 literoj (,,malinkluzive majusklojn"). Poste ili ,,arigis 100.000 vortojn da Esperanta novelaĵo verkitaj de 100 diversaj aŭtoroj" kaj el tiuj ili elektis ,,ĉiujn vortojn, kiujn uzis almenaŭ tri aŭtoroj, t.e. la komunajn vortojn". Tiamaniere ili ricevis kolekton de 78.622 vortoj, konsistantaj el 313.536 literoj. Mi supozas, ke ankaŭ tiu kolekto konsistis nur el minuskloj. Sed ne estas klare, ĉu ili neglektis la majuskle komenciĝantajn vortojn, aŭ nur transskribis ilin en la liston minuskle. Jen la rezulto en pocentoj:
a 12,53 o 7,21 t 4,68 u 3,27 f 0,89 ĝ 0,69 z 0,38
i 11,60 l 6,97 k 4,25 d 2,95 b 0,84 ŭ 0,67 h 0,36
e 8,95 s 6,71 m 3,33 p 2,62 ĉ 0,82 ŝ 0,62 ĵ 0,06
n 7,75 r 5,33 j 3,30 v 2,04 g 0,77 c 0,45 ĥ 0,004
(6) La statistiko de Sadler-Harry (Sadler 1959; Harry 1967). Mi kopias nur la statistikon de Sadler, ĉar en la resuma tabelo de Harry estas multaj kalkul-eraroj, do povas esti, ke ankaŭ liaj propraj donitaĵoj estas eraraj. Mi indikis (enparenteze) ankaŭ la alkalkulitajn fonemojn. R.O. = Relativa oft(ec)o.
fonemo R.O.% fonemo R.O.% fonemo R.O.% fonemo R.O.% fonemo R.O.%
a 13,17
e 9,13
i 8,40
o 8,13
n 7,50
t (+c+ĉ) 6,97
s (+c) 6,70
l 6,27
r 5,67
k 3,90
u (+ŭ) 3,70
d (+ĝ) 3,63
j 3,53
p 3,20
m 2,87
v 1,80
g 1,47
b 0,93
f 0,90
ŝ (+ĉ) 0,87
ĵ (+ĝ) 0,53
h 0,37
z 0,37
ĥ 0,00
(7) La statistiko de Pejno Simono pri 355.381-litera korpuso (Pejno 2000)
lit. %
A 12,08
O 9,9
E 9,63
I 8,27
N 7,91
R 5,9
S 5,89
L 5,76
T 5,75
K 3,86
U 3,31
P 3,13
M 3,08
D 2,8
J 2,62
V 1,82
G 1,33
F 1,27
B 1,19
C 1
Ĝ 0,72
Ĉ 0,71
Z 0,55
Ŭ 0,51
H 0,39
Ŝ 0,38
Ĵ 0,19
Ĥ 0,02
W 0,01
Y 0,01
X 0,01
Q 0,01
La ofteco de 22 fundamentaj literoj de ĉi lasta tabelo falas en la zonon F _ s de mia statistiko, kaj nur tiu de kvar literoj falas en la zonon de F _ 2s.
Bibliografio
Albault, André (1997): ,,Ĉu nia alfabeto tute taŭgas?" En: Heroldo de Esperanto 10 nov., 1-2.
Blanke, Detlev (1999): Retmesaĝoj kaj -sendaĵoj al O. Haszpra.
Ciliga, P. (1961): ,,Statistika tabelo de l' e-a vortaro (radikoj, afiksoj, finaĵoj, liternomoj)". En: Scienca Revuo 12, n-ro 1-2 (45-46), 38-44.
Collinder, Björn/Setälä, Vilho (1979): Fundamenta Esperanto sen supersignoj. Helsinki: aŭtoroj, proks. 12 p.
Gledhill, Christopher (1998): The Grammar of Esperanto. A corpus-based description. München: Lincom Europa, 100 p.
Harry, Ralph (1967): ,,Relativaj oftecoj de lingvaj elementoj en Esperanto". En: Scienca Revuo 19/2, 49-50.
Haszpra Otto (1998, 2000): Eszperantó az ábécétől a felsőfokig ['Esperanto de la aboco ĝis la supera grado']. Budapest: HEA (E-lingva versio por tradukontoj ricevebla tra retpoŝto de la aŭtoro), 280 p.
- (1999a): ,,Ofteco de la Esperantaj literoj". En: Debrecena Bulteno 114 (septembro) ,14-15.
- (1999b): Pri alternativa alfabeto de Esperanto. (Elektronika manuskripto ricevebla de la aŭtoro.)
Jung, Theo? (1926): ,,Statistiko. La ofteco de la literoj en la Esperanto alfabeto". En: Heroldo de Esperanto 48 (376).
Kelly, Tony (1994): ,,Ortografio". En: Nova Provo 7 (julio), 57-59.
- (1996): ,,Esperanto kaj la komputilo". En: Nova Provo 10 (oktobro), 84-86.
Lienhardt, Albert (1978): Optimala ortografio de la Internacia Lingvo Esperanto. O.E.O. Mulhouse, 122 p.
Máthé Árpád (1998): ,,Bibliografio de la Esperantaj periodaĵoj". En: Memorlibro. Felsőoktatási Koordinációs Iroda, Professzorok Háza, Budapest. ISBN 963 7647 66 X, 432-435.
McCoy, Roy (1999): Retmesaĝoj al O. Haszpra.
Pejno, Simono (2000):
Ofteco de Esperantaj literoj.
http://ourworld.compuserve.com/homepages/ profcon.
Sadler, Victor (1959): ,,Relativaj oftecoj de kelkaj lingvaj elementoj en Esperanto". En: Scienca Revuo 2-3, 67-72.
Sherwood, Bruce Arne (1983): ,,Komputila traktado de Esperanta teksto". En: Akademiaj Studoj. Bailieboro: Esperanto Press, 14-33.
Schlüter, K. 1972: Inversa vortaro de Esperanto laŭ la 6a eldono de PIV. (eldonis: L. Pickel), Nürnberg, 36 p.
Stancliff, Fenton (1932): ,,Ofteco de vortoj". En: Esperanto 11, 169 (13)
- (1933): ,,Literofteco en Esperanto". En: Heroldo de Esperanto 49 (754), 10 decembro.
Statistiko (ĉefe surbaze de J. Dietterle kaj ECO) 1933. Enciklopedio de Esperanto. Budapest: Literatura Mondo, 501-503.
Vortstatistiko 1933 (de F. Stancliff, resumita de EMBA). Enciklopedio de Esperanto. Budapest: Literatura Mondo, 565-570.
Waringhien, Gaston (1980): ,,La skribo kaj ĝiaj problemoj". En: Waringhien, Gaston: 1887 kaj la sekvo . tk-Stafeto, Antverpeno: La Laguna, 77-96.
Yung, Jon Walter 1995: Panoramo de la Universala Skribo. AEIOU, Tuluzo, 336 p.